!!!UPDATE!!! Since this post is still getting a lot of views, some of you might be interested in the outcomes of my experiments with the cross K-function. I used the function in 2 recent papers. Links to the articles are found on the Publications page. Juhász, L. and Hochmair, H. H. (2017). Where to catch ‘em all? – a geographic analysis of Pokémon Go locations. Geo-spatial Information Science. 20 (3): pp. 241-251 Hochmair, H.H., Juhász, L., and Cvetojevic, S. (2018). Data Quality of Points of Interest in Selected Mapping and Social Media Platforms. Kiefer P., Huang H., Van de Weghe N., Raubal M. (Eds.) Progress in Location Based Services 2018. LBS 2018. Lecture Notes in Geoinformation and Cartography (pp. 293-313) Berlin: Springer.
One of the research papers I’ve submitted recently (yes, about Pokémons!) dealt with spatial point pattern analysis. Visually it seemed that two of my point sets prefer to cluster around each other, in other words I suspected that Pokéstops have a preference of being close to Pokémon Gyms. Check the map below to see what I mean. Pokémon locations (cyan dots) are all over the place as opposed to Pokéstops (orange) that almost exclusively appear to be in the proximity of gyms (red).
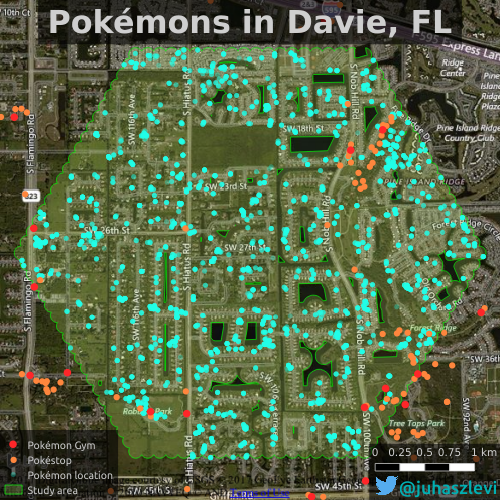
To confirm what’s obvious from the map, I used the bivariate version or Ripley’s K-function (a.k.a. the cross-K function) that can help us characterize two point patterns. As it turns out, it’s not as easy to interpret as I though it would be (at least with real world data) and I was trying to get my head around it for quite some time. As a result, I came up with a simple interactive visualization of this function to illustrate what it really means. If you’re anything like me and try to understand your stats instead of just reporting the results, you might want to read on more for some musings about the cross K-function.