Twitter, MongoDB and PostgreSQL are fun. Let’s put all together and see what we can do. Twitter is an evolving platform for many kinds of analyses. Anyone can access to the content and can be a data scientist for a while. If you’d like to play Big Brother just go ahead and start playing with it and you’ll find a lot of interesting things from people all over the world. Some says that NoSQL databases (such as MongoDB) are perfect for storing Big Data due its scalability and non-relational nature. The good thing in not being a computer scientist is that I can test them as an outsider – without knowing what I am really doing :).

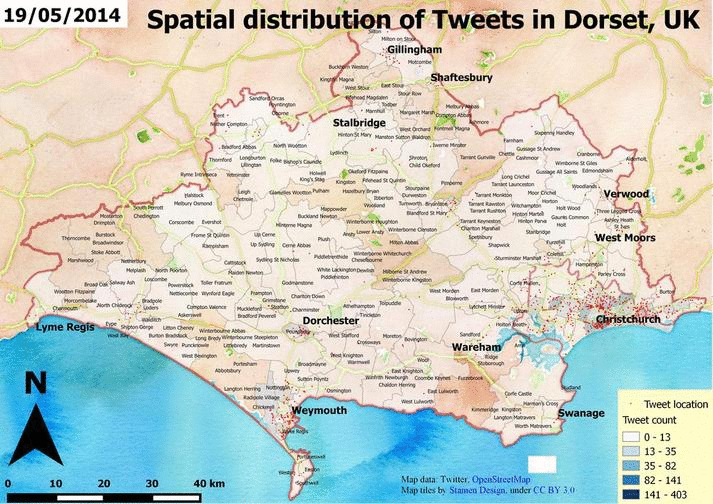
A little background: a few months before I had access to a database of approx. 200.000 tweets. It’s really nothing compared to some other databases but still big enough for retrieving data to be time-consuming. I was not responsible for the data collection but all data were coming from the Twitter Streaming API and my colleagues stored them both in a MongoDB collection and in a PostgreSQL table. They used the API’s location parameters for requesting data from an area located in the Southern part of the UK. Retrieving geographic data from PostgreSQL (with postgis) is relatively easy and well known but what about MongoDB? Can we even do it? I had no idea but it seemed to be fun enough to explore it. In these posts (maybe there will be 3 or so) I’ll show you how I visualized them. I’ll write about how I tried to extract some weather related information from them (come on, it’s the UK so I thought everyone tweets about the weather!) and lastly, I will show you how I tried to compare the two database engines in terms of speed.
Continue reading →