This Monday I attended my very first Maptime Miami Meetup where Matthew Toro talked about a potentially great addition to Miami’s OSM… buildings! What makes a map detailed and fancy looking? I think it’s buildings. And landuse. And POIs. Oh well, I could continue adding items to this list for days without even starting to talk about it, really. But in any case, buildings are without a doubt the very foundation of what we can call a detailed map. Sadly, Miami’s OSM is not what we can call nice and detailed in its current state. It instantly becomes clear when you look at the map that it needs some improvement. But you know what? That’s the fun part of collaborative mapping. It’s really up to us how we build a useful map database and how detailed we want it to be. It’s us, regular people who add restaurants, bike lanes, shops and many other things we care about. Long story short, the Meetup was about importing a publicly available building dataset and making it an integral part of OpenStreetMap. I’ve decided to participate in the process, and I planned to help out with some basic stuff, throwing some ideas, maybe writing some code. You know, nothing fancy. At least that’s what I imagined. But as things rarely turn out the way we want them, now I’m the tech lead on this. Big words, I know, but they’re not mine.
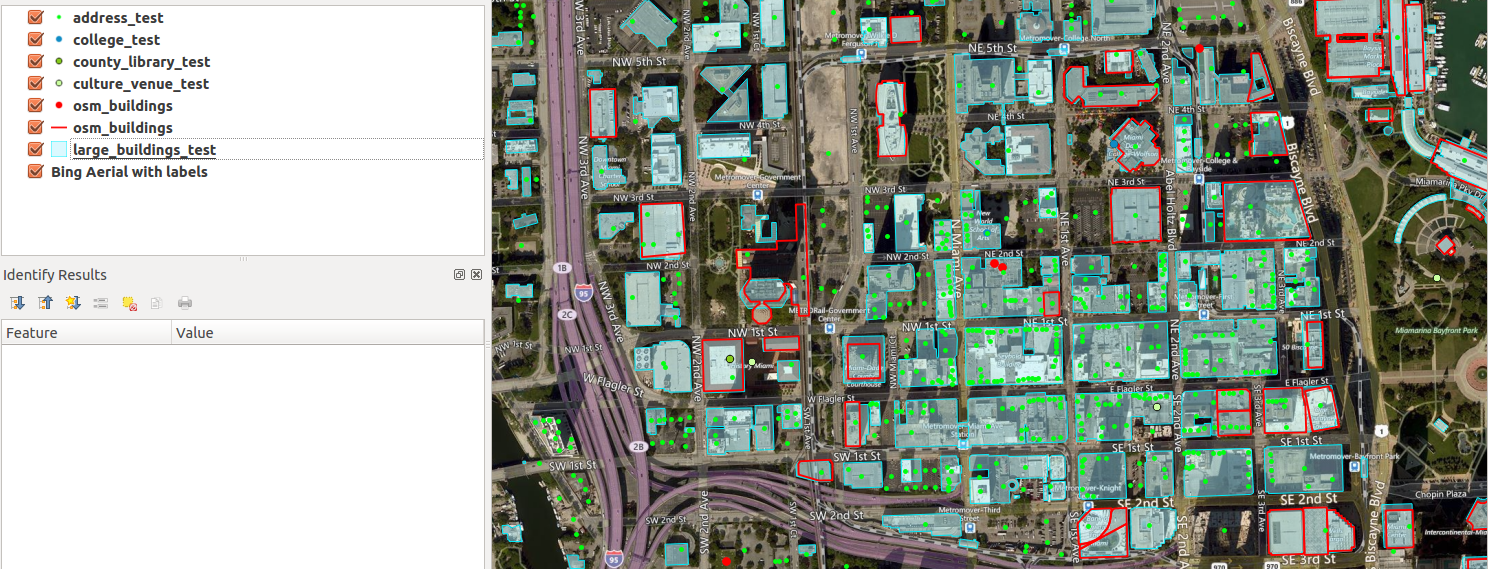
Red outline: current OSM buildings. Cyan spots: buildings to be imported. Now, that’s a lot of new buildings to add!