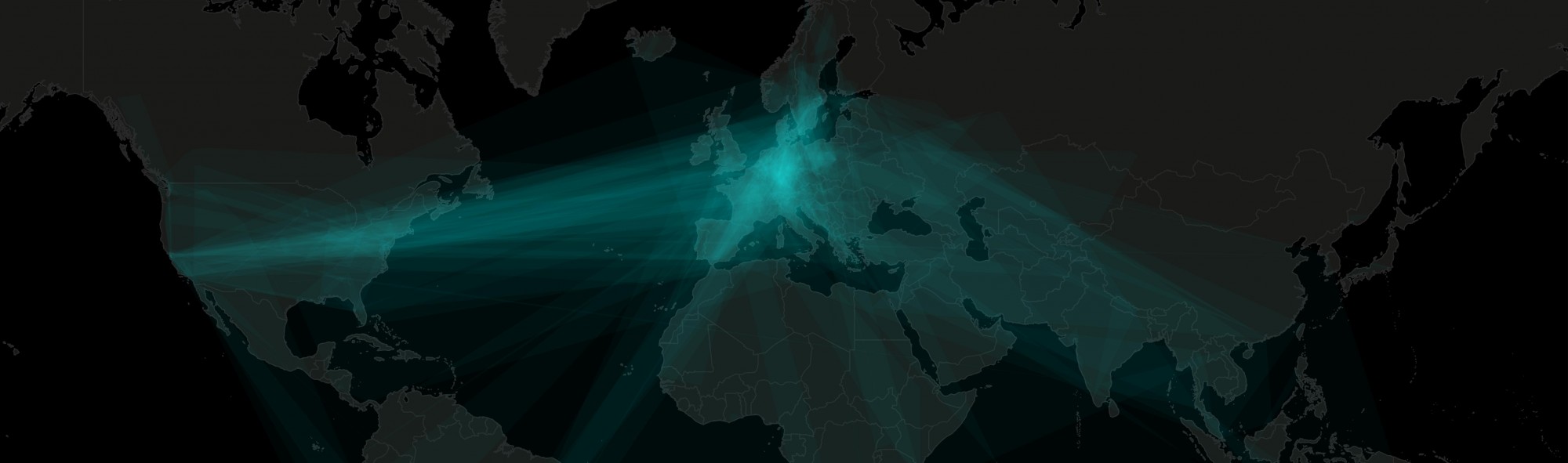
In the previous post, I’ve introduced the topic and technology. Now, it’s time to define the problem and methods. Next entries will discuss how to access to MongoDB and how to retrieve geocoded Tweets. I will focus on tweets that are somehow related to the weather using the simplest approach possible – querying their content for the keyword ‘weather’. I will create some nice visualizations later on, an animated gif and a wordcloud that can help us understand what is behind the scenes. You’ll find some code snippets and screenshots so feel free to scroll down to those if you’re not interested in long discussions. So, let’s grab the data from MongoDB and see what’s inside! There’s quite much to do.
Data access
In MongoDB a database can contain collections that are groups of documents. The same that we call table in an RDBMS with the difference that these documents does not necessarily have the same schema. They can be different. As a first task, we set up a connection, access to a database and collection and figure out what’s inside. This is how we do it.
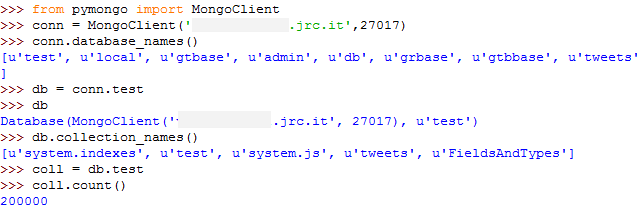 For the rest of this tutorial, I will use the test database from the connection show above. I will refer to the test collection in the test database as db.test instead of using coll, as it is more like the way we use it in the mongo shell. The u before each string stands for Unicode in Python. We can call the find_one() method on a collection which returns the first document of the collection so we can look into it. This is a python dictionary which contains key-value pairs, just like a JSON object.
For the rest of this tutorial, I will use the test database from the connection show above. I will refer to the test collection in the test database as db.test instead of using coll, as it is more like the way we use it in the mongo shell. The u before each string stands for Unicode in Python. We can call the find_one() method on a collection which returns the first document of the collection so we can look into it. This is a python dictionary which contains key-value pairs, just like a JSON object.
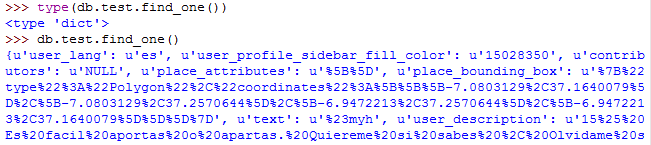 This is how a document looks in the mongo shell if we use the same method on a collection – implemented as db.test.findOne()
This is how a document looks in the mongo shell if we use the same method on a collection – implemented as db.test.findOne()
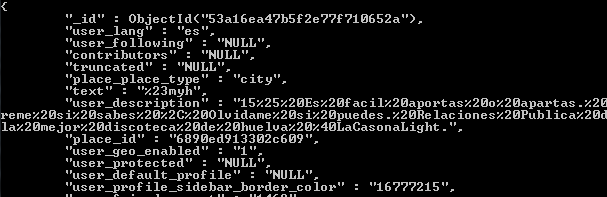 So, we have lots of keys and values. We can list the keys using the keys() method on a python dictionary. db.test.find_one.keys() shows the keys we have. We are interested in the “text”, “created_at” and some location parameters (“coordinates_coordinates_longitude”, “coordinates_coordinates_latitude”). You can’t see these coordinates in the screenshots but believe me, they’re there and they just contain latitude and longitude coordinate pairs. All of our values are Unicode strings, and the values come with a percentage encoding. That is pretty annoying but we’ll get rid of them later. This is not the way Twitter Streaming API provides data but is specific to the software that which was used for data collection. Anyways, I leave this part here.
So, we have lots of keys and values. We can list the keys using the keys() method on a python dictionary. db.test.find_one.keys() shows the keys we have. We are interested in the “text”, “created_at” and some location parameters (“coordinates_coordinates_longitude”, “coordinates_coordinates_latitude”). You can’t see these coordinates in the screenshots but believe me, they’re there and they just contain latitude and longitude coordinate pairs. All of our values are Unicode strings, and the values come with a percentage encoding. That is pretty annoying but we’ll get rid of them later. This is not the way Twitter Streaming API provides data but is specific to the software that which was used for data collection. Anyways, I leave this part here.
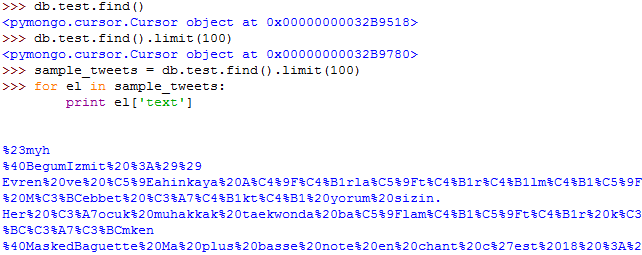
If we want to access all individual documents, we can uses cursor objects and iterate through the cursor. This is a common method. Doing so will enable to read, modify and analyze the content of a collection. We can create a cursor by calling the find() method on a collection. Without arguments, find() will return a cursor for the collection in whole, but find() can also take an argument with a query expression. Queries are not like that we are used to use in SQL. MongoDB has a simple JSON-like query language in which we pass keys and values as a python dictionary to the server. We can use a great set of query operators (comparison, logical, and even geospatial operators exist) . See the documentation here and here.
I limited the documents to 100 with the limit() method and printed the value of the text field in for each element. As you can see, the percentage encoding is pretty annoying. We can unquote the text using the urllib2 package for python, but first, we have to encode Unicode text to ascii.
 Now, get rid of the percentage encoding:
Now, get rid of the percentage encoding:
 Special characters does not seem to be appeared in a nice way, but we will use the tweets for the UK. We can also query our dataset by the “user_lang” key in order to get only the tweets in English. In English, some of the emoticons/smileys will cause some problems but we don’t care about it right now. Instead of ignoring Unicode errors, we can also use ‘replace’, ‘xmlcharrefreplace’, ‘backslashreplace’ and ‘strict’ them. You can read about in in the python doc.
Special characters does not seem to be appeared in a nice way, but we will use the tweets for the UK. We can also query our dataset by the “user_lang” key in order to get only the tweets in English. In English, some of the emoticons/smileys will cause some problems but we don’t care about it right now. Instead of ignoring Unicode errors, we can also use ‘replace’, ‘xmlcharrefreplace’, ‘backslashreplace’ and ‘strict’ them. You can read about in in the python doc.
It’s time to query the collection for the tweets that contain the keyword weather for further use. We will pass a python dict to the find() method in which we ask the server to match the ‘text’ property of each document to a regular expression. It says that there were only 310 tweets out of the 200.000 that contained our keyword. Iterating through the cursor and printing out the tweets can give us a sense of what people were talking about.
 Another interesting thing would be to see these tweets on a map. Read the next post if you’re still interested in.
Another interesting thing would be to see these tweets on a map. Read the next post if you’re still interested in.

